예전에 했던 DynamoDB 로 DB를 구성할때 했던 세미나 내용과 사용햇던 경험을 적어본다.
우선 간단하게 핵심만 알고 들어가보도록 하자 🚩
DynamoDB란?
Amazon DynamoDB는 Amazon Web Services(AWS)가 제공하는 완전 관리형 NoSQL 데이터베이스 서비스입니다.
- 주요 특징
- 확장성: DynamoDB는 자동으로 데이터를 여러 서버에 분산 저장하므로 테이블 크기를 미리 정의할 필요가 없으며, 사용자는 데이터베이스를 수평으로 확장할 수 있으며, 어떤 크기의 데이터에도 대응 가능
- 고성능과 저지연: DynamoDB는 밀리초 이하의 지연을 제공하며. 이는 캐싱, 백엔드 속도 개선, 데이터 동기화 등에 도움
- 키-값 데이터 모델: DynamoDB는 유연한 데이터 모델을 지원하여 다양한 비즈니스 요구 사항에 맞게 데이터를 모델링 가능
- 완전 관리형 서비스: DynamoDB는 서버 관리, 패치 설치, 데이터 복제, 백업 등과 같은 기능을 자동으로 처리 따라서 개발자는 이러한 운영 작업에 신경 쓸 필요 없이 애플리케이션 개발에 집중할 수 있음
- Auto-Scaling: DynamoDB로 들어오는 워크로드에 따라서 처리량(RCU / WCU)을 Auto-Scaling 지원, 또 다른 요금 정책인 온디맨드와는 달리 정해진 워크로드수 보다 처리량이 늘어나면 자동으로 정해진 수만큼 Auto-Scaling을 해준다.
- 리전별 데이터 복제: 기본적으로 1개의 Region에 3개의 복제본을 만들어 놓기 때문에 한 곳에서 장애가 나더라도 가용성을 유지할 수 있는 특징이 있음, 만약 따로 백업을 하고 싶다면, 다른 리전에도 가능함
또한, 각 리전별로 해당 다이나모를 접근하고 싶다면 해당 리전에 DB를 복제해놓고 서버에서 IP를 기준으로 해당 리전의 DB에 접근하게하는 것도 좋다. - 빠른 응답시간: 빠르고 일관된 응답시간(Single-digit millisecond latency) 제공, 레이턴시를 조정할 수 도있음
- 주요 구성
- 테이블(Table)
- 항목(Item): 테이블 내의 개별 데이터 레코드를 의미 (SQL 기준 row)
- 속성(Attribute): 항목 내의 데이터 항목입니다. 이는 이름과 값의 쌍으로 구성 (SQL 기준 컬럼)
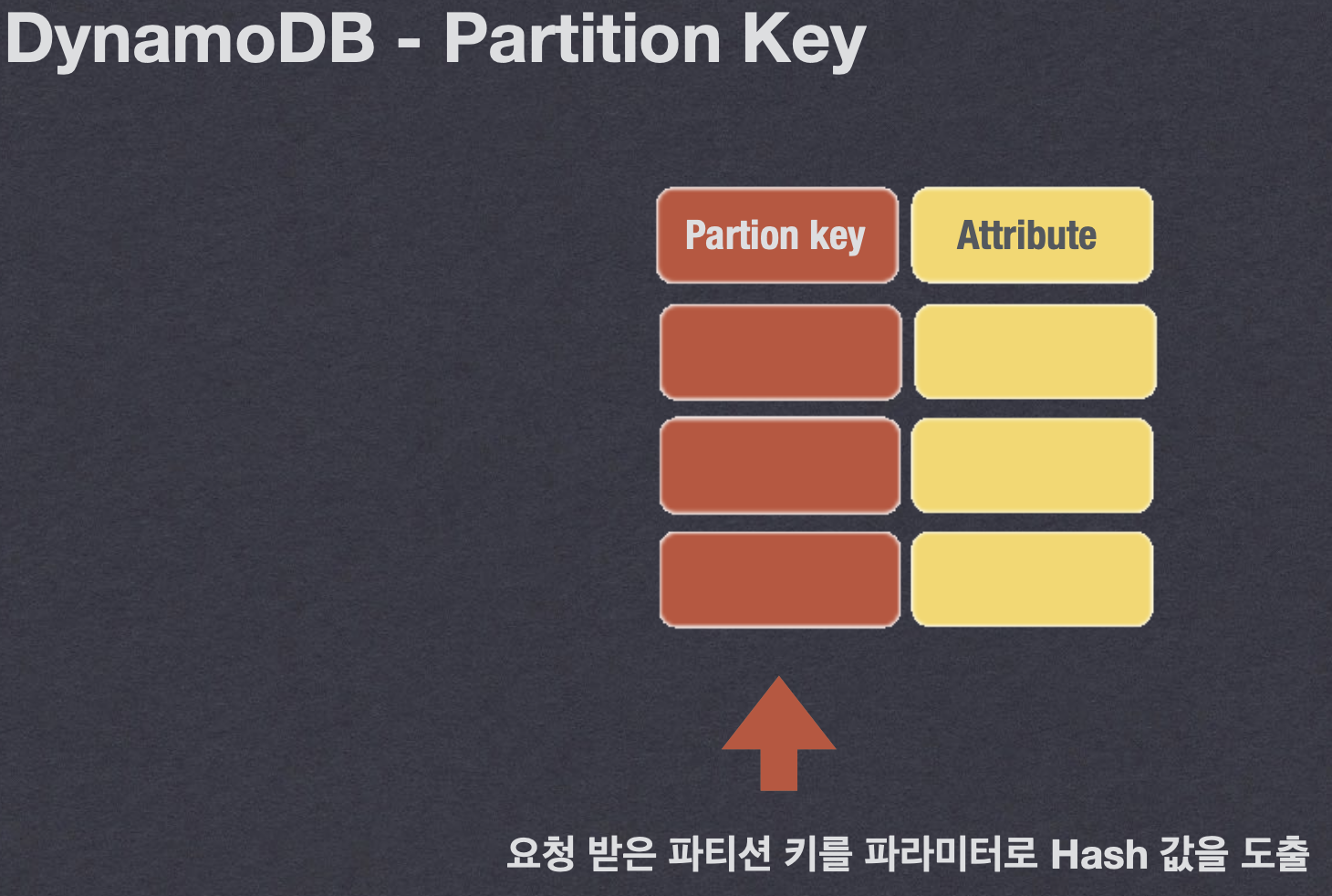
- 프라이머리 키(Primary Key): 각 항목을 고유하게 식별하는 데 사용되는 키 이는 파티션 키만으로 구성하거나 파티션 키와 정렬 키의 조합으로 복합키로 구성할 수 있음
- 파티션 키(Partition Key): 프라이머리 키의 첫 번째 부분입니다. DynamoDB는 파티션 키 값을 기반으로 데이터를 분산
- 정렬 키(Sort Key): 프라이머리 키의 두 번째 부분입니다. 정렬 키를 사용하면 파티션 키 값 내에서 항목을 정렬가능
- Sort key를 사용시에는 복합키 구성이기에 파티션키를 중복으로 사용가능하다.
- 인덱스(Index): 데이터를 접근하기에 Primary Key(PK + SK)만으로는 부족하기 때문에 보조 인덱스(Secondary Index)를 추가적으로 제공, 보조 인덱스는 LSI (Local Secondary Index)와 GSI(Global Secondary Index) 두 가지로 나누어진다.
- LSI
- 테이블 생성 시에만 생성 가능하며, 삭제 불가능
- 용량은 10GB로 제한
- 파티션 내 테이블 데이터와 함께 저장
- 테이블과 동일한 Partition Key를 사용하며, Sort Key 지정
- GSI
- Partition Key를 필수 설정하고, Sort Key는 선택 사항
- 테이블 생성 후에도 생성/삭제 가능
- 용량 제한 없음
- 테이블 외 인덱스 데이터 따로 저장
- LSI
- 정리
- 유연한 NoSQL 데이터베이스 서비스
- 대규모 애플리케이션에서 데이터를 빠르고 안정적으로 처리할 수 있는 능력을 제공
- 아무런 사전 설정 없이 데이터베이스를 쉽게 생성하고 확장할 수 있음
- 애플리케이션 개발에 더 집중하기 편함
- 성능과 확장성에 대한 걱정을 줄일 수 있음
- 보충 설명을 위한 이미지

위에 같이 간단하게 DynamoDB에 알아 봤다면, 이제 본격적으로 모델링과 사용을 해보도록 하자. 😎
왜 DynamoDB 사용하는가?
회사의 내부 기술이라 다 서술하기는 어렵지만, 간단하게 설명하면 자주 읽고, 쓰기가 반복되면 정해진 유형이 없다.
또한, 저장된값은 재활용을 자주하고, 응답시간이 빨라야하는 서비스였기에 차용했다.
DynamoDB 모델링 - 요구사항 분석
AWS 공식 홈페이지에 있는 모범사례를 보고 참고 했다.
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/bp-relational-modeling.html
DynamoDB의 관계형 데이터 모델링 모범 사례 - Amazon DynamoDB
DynamoDB의 관계형 데이터 모델링 모범 사례 기존의 관계형 데이터베이스 관리 시스템(RDBMS)은 데이터를 정규화된 관계형 구조로 저장합니다. 관계형 데이터 모델의 목적은 정규화를 통해 데이터
docs.aws.amazon.com

위와 같은 태그 방식으로 설계를 진행했다.
예시는 아래와 같다.
| PK | SK | data | etc |
| 유저명#대화 | 대화#대화내용 | { 서버: 어디어디 } | ... |
위와 같은 방식으로 해보았고, 실제로 태그방식인지라 직관적이었다.
DynamoDB 모델링 - 설계

구성을 했다면, 실제로 작동되는지 테스트를 해봐야한다.
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/workbench.settingup.html
Download NoSQL Workbench for DynamoDB - Amazon DynamoDB
Java Runtime Environment (JRE) version 8.x or newer is required for running DynamoDB local.
docs.aws.amazon.com
AWS DynamoDB 전용 SQL 에디터를 제공해준다. 이걸 사용해서 먼저 테스트
DynamoDB 모델링 - 성능 테스트
실은 이전부터 DynamoDB를 사용했다. 개선을 하면서 성능 개선을 하고 싶었다.
이전 모델링은 사실 저장 자체를 많이 할 일이 없었고, 보통 저장되고나면 읽는데 많은힘을 쏟앗기에 item에 많은 내용을 저장했다.
언제나 그렇듯.. 서비스를 개선하면서 요구사항은 변하기마련 🫠 확장성을 고려해 전체적으로 개선하게 되었다.
그 결과

v1 -> v2로 이관하면서 성능 테스트를 해보았다. (훨씬 빠름 👍🏻)
DynamoDB 모델링 - 개발 및 코드 작성 (PartiQL)
DynamoDB SQL처럼 비슷하게 코드를 사용할 수 있다.
https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/ql-reference.html#ql-reference.what-is
PartiQL - Amazon DynamoDB용 SQL 호환 쿼리 언어 - Amazon DynamoDB
PartiQL - Amazon DynamoDB용 SQL 호환 쿼리 언어 Amazon DynamoDB에서는 SQL 호환 쿼리 언어인 PartiQL을 사용하여 Amazon DynamoDB에서 데이터를 선택, 삽입, 업데이트, 삭제할 수 있습니다. PartiQL을 사용하면 DynamoDB
docs.aws.amazon.com
PartiQL - Select 문

SQL가 매우 흡사하지 않은가?
라이브러리를 사용한 커맨드도 좋지만, 회사에서는 ORM을 주로 사용한다. 그러다 간혹가다가 복잡한 쿼리가 있을 수 있기에, 가끔식은 바로 쿼리 형태로 작성하기도 한다.
이번에 개선하면서, 좀더 직관적으로 사용할 수 있도록 쿼리 형태로 선언해 보기로 했다.
추가적으로 Map 형태로 된 속성은 조회시 "" 로 묶어줘야 검색이 가능하다.

DynamoDB 모델링 - 결과
매우 흡족 🫶
실제로 개발하고 1년이 다되가는 시점에 작성한 글이다. 1년 동안 DB를 더확장할 일도 없었으며, 이슈도 없었다. 🤟
'개발노트 > 공부' 카테고리의 다른 글
| RabbitMQ, Redis-BullQueue 에 대한 고찰 (0) | 2023.06.01 |
|---|
